Mathematics - a practical odyssey¶
ToC
Set theory¶
Notations¶
Set builder notation for representing a set: $$ G = \{ x\mid x < 0 ~and~ x \in R \} $$ which is read as 'the set of all x, such that x is less than 0 and x is a real number'.
Cardinal number of a set is the number of elements in it. It is denoted as n(A). An empty set has 0 elements. It is represented as $\phi$ or as {}. Universal set is always represented as U.
A is a proper subset of B, if all elements of A are in B and B has more elements than A. It is represented as $A \subset B$. A is an improper subset of B if A and B have the same elements. A not a subset is represented a $A \not\subset B$. Thus $$ A \cup B = \{ x \mid x \in A ~or~ x\in B\}$$ $$ A \cap B = \{ x \mid x \in A ~and~ x\in B\}$$
Intersection of sets represents the common elements and is written as $ A \cap B$. Union of sets represents all elements, without repetition and is written as $A \cup B$.
Two sets are Mutually exclusive, if there are no common elements. Written as $ A \cap B = \phi $.
Cardinal number formula for union of two sets¶
$$n(A \cup B) = n(A) + n(b) - n(A\cap B)$$
Complement of a set is the set of all elements not in that set, but in Universal set. It is represented as $$ A' = \{x\mid x \in U ~and~ x \not\in A \}$$ $$ n(A') = n(U) - n(A)$$
De Morgan's laws¶
For any two sets A and B (no need to be independent or mutually exclusive) $$ (A\cup B)' = A' \cap B'$$ $$ (A\cap B)' = A' \cup B'$$
Permutations and combinations¶
Fundamental principle of counting¶
The number of possible ways in which you can choose a 4 digit PIN number: Here, you can repeat numbers (or, your choices are replaced once you chose them so they can be chosen another time). Here, you simply raise the choices by number of selections.
Number of ways to select 4 digit PIN = 10 x 10 x 10 x 10 = 10,000.
Permutations¶
Selection without replacement (no repetition) and order of selection is important, meaning, if you change the order, you can count that selection as a whole new choice. The formula is
$$ _{n}P_{r} = \frac{n!}{(n-r)!}$$ where n is number of items in the pool and r is the number of choices to be made.
The number of ways to choose the first 3 places from a pool of 10 contestants: $$_{10}P_{3} = \frac{10!}{7!} = 720$$
# use itertools to calculate permutations in Python
from itertools import permutations
# create list of items in pool
n = list(range(1,11))
npr_choices = list(permutations(n,3)) # since you get back a iterable
print(len(npr_choices))
720
Combinations Selection without replacement and order is not important. If you change the order, that choice is not counted as a new choice. Thus, there are generally fewer combinations than permutations possible in a given scenario. Exceptions are narrow choices like choose 1 or 0 items from a pool of items. In this case, number of permutations and combinaions are the same.
$$ _{n}C_{r} = \frac{n!}{r! (n-r)!}$$
Thus, the various combinations of choosing 3 balls from a bag of 10 balls are: $$ _{10}C_{3} = \frac{10!}{3! \cdot 7!} = 120$$
# use combinations method from itertools module
from itertools import combinations
n = list(range(1,11))
ncr_choices = list(combinations(n,3))
print(len(ncr_choices))
120
Probability¶
Probability is the measure of likelihood of an event happening. In general, it is the ratio of number of outcomes in the event E to the total number of possible outcomes. Thus
$$ p(E) = \frac{n(E)}{n(S)}$$
Probability is a computed value. If you are conducting an empirical study, you can measure probability of an event by measuring the relative frequency of that event. The law of large numbers states that
If an experiment is repeated a large number of times, the relative frequency of an outcome will tend to be close to the probability of the outcome.Probability rules¶
$$ p(\phi) = 0 \\ p(S) = 1 \\ 0 \leq p \leq 1 $$
Combinatronics and probability¶
Probability of being dealt 4 Aces in poker First find the sample space. Sample space includes all possible ways of selecting 5 cards from a pack of 52.
Thus, n(S) = $_{52}C_{5} = 2,598,960$.
Now, n(E) = number of ways of selecting 4 aces + 1 any other card.
n(E) = $_{4}C_{4} \cdot _{48}C_{1}$
p(E) = n(E) / n(S) = (4*48)/2,598,960 = 0.00001847
Probability of being dealt 4 of a kind.
The, n(S) remains same. But n(E) is expanded 13 times as there are 13 different ways to select a 4 of a kind in a single pack of cards.
p(E) = 13* (probability of 4 aces)
Probability of getting 5 hearts.
The n(S) remains same as $_{52}C_{5}$. Now the n(E) is written as $_{13}C_{5}$ as there are 13C5 number of ways to select a set of 5 hearts.
Thus, p(E) = 13C5 / 52C5 = 0.0004951
Conditional probability¶
Conditional probability of event A given event B is written as $$p(A|B) = \frac{n(A\cap B)}{n(B)} $$
dividing both numerator and demoninator of right side by n(S), we can rewrite this as
$$p(A \cap B) = p(A|B) \cdot p(B) $$
Understanding the difference between 'A given B' and 'A and B'¶
Two cards are dealt from a pack of cards, find the probability that
- both cards are hearts. This is $p(A \cap B)$
- second card is heart, given first is a heart. This is looking for the odds of the 2nd card. It is $p(A|B)$ where A is second card and B is first card being heart.
The probability of selecting 1st heart is 13/52. Hence:
$$p(B) = \frac{13}{52}$$
Since the 1st card is heart, you are left with 12 hearts and 51 total cards. So the probability of selecting another heart is: $$ p(A|B) = \frac{12}{51} = 0.2352$$
Thus:
$$p(A \cap B) = \frac{12}{51} \cdot \frac{13}{52} = 0.0588$$
We can also calculate probability of both hearts without conditional probability using combinatronics as below:
$$p(A \cap B) = \frac{_{13}C_{2}}{_{52}C_{2}} $$
$$p(A \cap B) = \frac{13}{52} \cdot \frac{12}{51} $$
Dependent and Independent events¶
If A and B are independent, then knowing B occurred does not affect the probability of A. Thus:
Conversely, if $p(A|B) \neq p(A)$ then A and B are dependent.
An example of independent events is, "find the probability of getting a 6 when tossing a pair of die, given the first also yielded a 6". Here the event of getting a 6 in one or first try does not affect getting 6 another time. Hence, they are simply independent events.
Using cardinal number of sets, in set theory,
for mutually exclusive A and B events, the $p(A \cap B) = 0$ thus, $$ p(A \cup B) = p(A) + p(B)$$
Using De Morgan's laws,
and
$$p(A' \cup B') = p(A \cap B)' $$
Statistics¶
Measures of central tendency¶
Population mean $\mu$ and median cannot be calculated. We generally calculate the sample mean and median.
$$Sample ~ mean: \bar x = \frac{\sum x}{n} $$
$$Sample ~ median: ~ L = \frac{n+1}{2} $$
Measures of dispersion¶
Variance is the squared deviation from the mean.
$$Sample ~ variance: s^{2} = \frac{\sum{(x - \bar x)^{2}}}{n-1}$$
$$Sample ~ standard ~ deviation: s = \sqrt{\frac{\sum{(x - \bar x)^{2}}}{n-1}}$$
Normal distribution¶
If you plot the outcomes of a continuous random variable (of a process occurring in nature, like rainfall), it takes the shape of a bell curve, with values close to mean occurring more often than those farther from it. Since the curve represents the the probabilities of various outcomes, it is also a probability distribution.
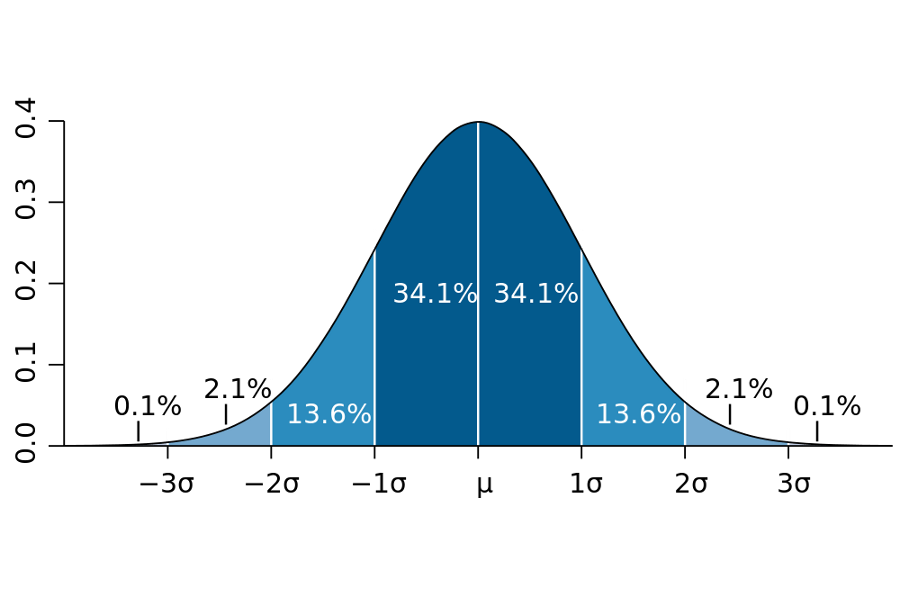
The Area under the curve = 1. Here $\mu$ is population mean and $\sigma$ is population standard deviation. Thus, 68% values vall within $\mu \pm 1 \sigma$ and 95% with $\mu \pm 2 \sigma$ and 99.74% within $\mu \pm 3 \sigma$. We use the Z table to find the area / probability for any other values of x.
Transformation to standard normal¶
The Z table gives probabilities for standard normal dist ($\mu = 0$ and $\sigma=1$). To transfrom a normal dist with any other mean and SD, use the formula
$$ z= \frac{x - \mu}{\sigma}$$
where x is the value in the given distribution and z is the value in std. normal dist.
Central limit theorem¶
Since it is hard to find the population mean, SD, we use the CLT. According to CLT, means of a large number of samples is normally distributed around the population mean. Same applies for the SD and other measures.
Level of confidence¶
"We might say we are 95% confident the maximum error of a poll is plus or minus 3%". This means, if 100 samples are analyzed, 95 of them would differ from population by under 0.03 of that measure, and 5 would be greater than 0.03.